ダイジェスト認証, スマートポインタ, Ubuntu, タイマ, テトリス, Queue, UTF-32
その他
本稿では, Digest認証, およびセッション認証の欠点を互いに補うあう, 二つを組み合わせた認証方法を提案する.
まず, Digest認証とセッション認証について簡単に説明したのち, 本題に入る.
公式リファレンスを参考しつつ, Ubuntu 上にNVIDIA GPU ドライバ, CUDA, cuDNNを入れて, tensorflow をGPUで動かす方法を, フローチャートで進めます.
OSがタスクの切り替えを行うためには, 定期的にOSが現在実行中のタスクの処理を中断してタスク切り替え処理を行う必要があります.
ここでは, このようなOSが定期的に割り込み処理を行う方法を説明します. また, 割り込み時の処理について説明します.
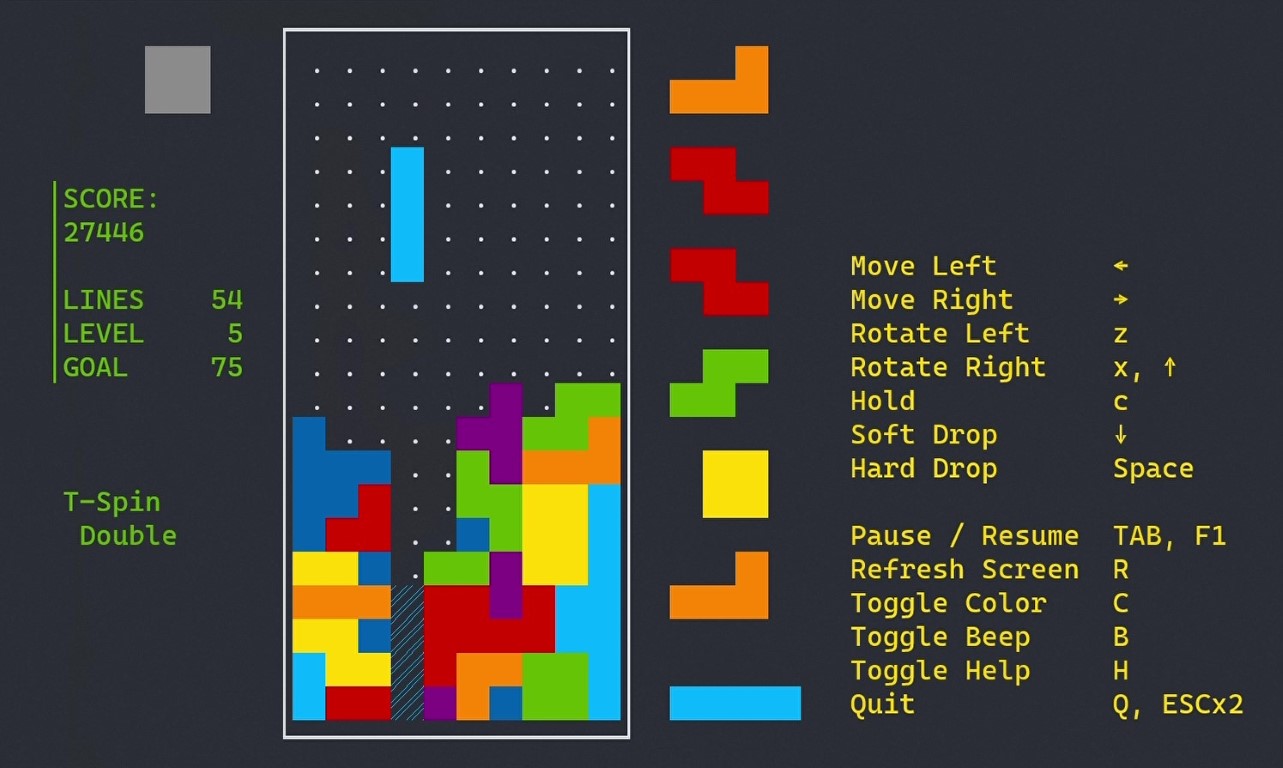
bashでもなく, zshでもなく, cshでもなく, 純粋なshで動く, テトリスの公式ガイドラインにそったテトリスを作りたい.
サイズ固定の待ち行列ライブラリを紹介します.
このQueueは, 以下の特徴を持ちます.
- std::queue が使用できない状況下での待ち行列の使用
- メモリを贅沢に使用しないサイズ固定待ち行列
- 例外処理に対応していない環境下での使用
本稿では, C++でバージョンに左右されずに文字を扱うために, 以下の機能を持つライブラリを紹介します.
- 型依存しないUTF-8, UTF-16, UTF-32間の相互変換
- UTF-8, UTF-16文字(コードポイント)ごとのイテレート
- 標準イテレータを使ったイテレート
- 型依存しないイテレータの対応
サイズ固定の待ち行列ライブラリを紹介します.
このQueueは, 以下の特徴を持ちます.
- std::queue が使用できない状況下での待ち行列の使用
- メモリを贅沢に使用しないサイズ固定待ち行列
- 例外処理に対応していない環境下での使用
本稿では, C++でバージョンに左右されずに文字を扱うために, 以下の機能を持つライブラリを紹介します.
- 型依存しないUTF-8, UTF-16, UTF-32間の相互変換
- UTF-8, UTF-16文字(コードポイント)ごとのイテレート
- 標準イテレータを使ったイテレート
- 型依存しないイテレータの対応
広く使われているUnicode規格を理解し, エンコーディングの手法, UTF-8, UTF-16, UTF-32, を理解して, 多言語の文字コードを扱えるようになることを目指します. 具体的に, UTF-8, UTF-16, UTF-32間の変換方法をC++で実装し, 手法はできるだけ速い方法を用います.
サイズ固定の待ち行列ライブラリを紹介します.
このQueueは, 以下の特徴を持ちます.
- std::queue が使用できない状況下での待ち行列の使用
- メモリを贅沢に使用しないサイズ固定待ち行列
- 例外処理に対応していない環境下での使用
サイズ固定の待ち行列ライブラリを紹介します.
このQueueは, 以下の特徴を持ちます.
- std::queue が使用できない状況下での待ち行列の使用
- メモリを贅沢に使用しないサイズ固定待ち行列
- 例外処理に対応していない環境下での使用
本稿では, C++でバージョンに左右されずに文字を扱うために, 以下の機能を持つライブラリを紹介します.
- 型依存しないUTF-8, UTF-16, UTF-32間の相互変換
- UTF-8, UTF-16文字(コードポイント)ごとのイテレート
- 標準イテレータを使ったイテレート
- 型依存しないイテレータの対応
広く使われているUnicode規格を理解し, エンコーディングの手法, UTF-8, UTF-16, UTF-32, を理解して, 多言語の文字コードを扱えるようになることを目指します. 具体的に, UTF-8, UTF-16, UTF-32間の変換方法をC++で実装し, 手法はできるだけ速い方法を用います.
本来手動でメモリ管理しなければならない動的なオブジェクトを、スコープによって自動でメモリ管理するもの。
本稿では, C++でバージョンに左右されずに文字を扱うために, 以下の機能を持つライブラリを紹介します.
- 型依存しないUTF-8, UTF-16, UTF-32間の相互変換
- UTF-8, UTF-16文字(コードポイント)ごとのイテレート
- 標準イテレータを使ったイテレート
- 型依存しないイテレータの対応
広く使われているUnicode規格を理解し, エンコーディングの手法, UTF-8, UTF-16, UTF-32, を理解して, 多言語の文字コードを扱えるようになることを目指します. 具体的に, UTF-8, UTF-16, UTF-32間の変換方法をC++で実装し, 手法はできるだけ速い方法を用います.
広く使われているUnicode規格を理解し, エンコーディングの手法, UTF-8, UTF-16, UTF-32, を理解して, 多言語の文字コードを扱えるようになることを目指します. 具体的に, UTF-8, UTF-16, UTF-32間の変換方法をC++で実装し, 手法はできるだけ速い方法を用います.
本来手動でメモリ管理しなければならない動的なオブジェクトを、スコープによって自動でメモリ管理するもの。