校正, アルゴリズム, テトリス, 検索エンジン, アセンブリ, CUDA
その他
本稿は, 筆者が今まで文を書いてきて, 先輩, 先生方から言われた文の校正内容をまとめたものです. 文の意味で校正をするのではなく, 文を文字列として扱いプロトコル的に校正します.
広く使われているUnicode規格を理解し, エンコーディングの手法, UTF-8, UTF-16, UTF-32, を理解して, 多言語の文字コードを扱えるようになることを目指します. 具体的に, UTF-8, UTF-16, UTF-32間の変換方法をC++で実装し, 手法はできるだけ速い方法を用います.
OutlineTextのパーサ(Parser)について
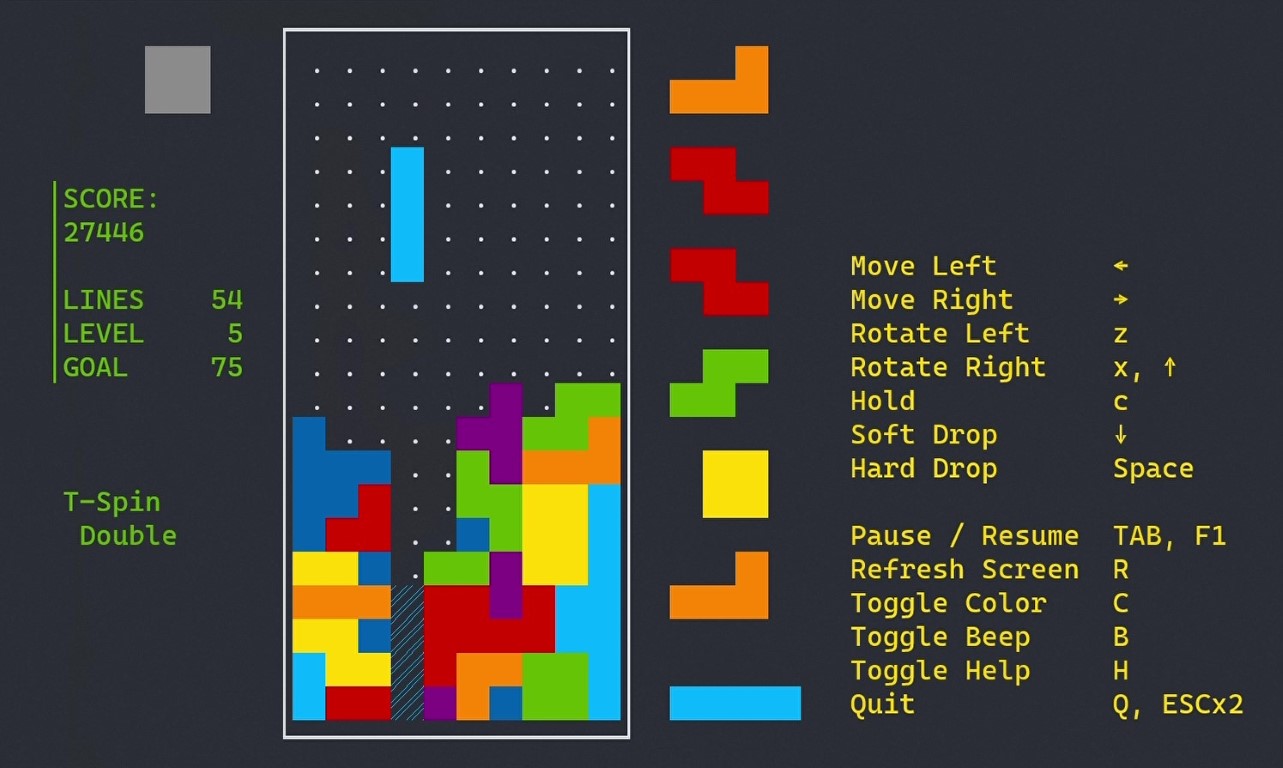
bashでもなく, zshでもなく, cshでもなく, 純粋なshで動く, テトリスの公式ガイドラインにそったテトリスを作りたい.
インターネット上で調べものをするとき, 検索エンジンを使用してインターネット上にある膨大なコンテンツを絞り込みます. ただし, 日本国内で検索エンジンのサービスを利用すると, 日本を対象としたコンテンツが検索対象になります. そのため, 英語で書かれた最新の技術情報や, 論文, 公式のリファレンスがヒットしずらい問題があります.
本稿では, 日本国内にいながらも, 海外の検索エンジンサービスを利用できる方法を提示します.
データベースを使わないで, あいまい検索を実現するPHPライブラリ
タスクの切り替えをする際, その時のCPUの状態を保存する必要があります. このCPUの状態をコンテキストと呼びます. あるタスクから離れるときはコンテキストの保存を行い, あるタスクに復帰するときはコンテキストの復帰を行います.
ここでは, コンテキストに関する詳しい説明とコンテキストの保存と復帰の方法について説明します.
公式リファレンスを参考しつつ, Ubuntu 上にNVIDIA GPU ドライバ, CUDA, cuDNNを入れて, tensorflow をGPUで動かす方法を, フローチャートで進めます.